|
Lukasz Michalski I'm a Software Engineer at AMD, where I work on optimization of rendering pipelines using modern machine learning solutions in FidelityFX: upscaling, frame generation, ray regeneration, radiance caching, on proprietary AMD RDNA graphics accelerator architectures. Previously research student at CERN CMS experiment (Next Generation Trigger). Focused on benchamarking heterogeneous architectures towards 40 MHz processing; efficient heterogeneous ML inference inside cmssw framework; new tau tagging approach with parallel clustering. At Intel R&D, I worked on GPU Software Development (AI/CV) in AI Graphics Software for DirectX 3D team. At Nokia, I contributed to internal tools for analyzing eNB machine logs and developed an in-house source code management system for SoC hardware solutions. I hold an MSc in Artificial Intelligence, BEng in Computer Engineering from Wroclaw University of Science and Technology Email / CV / LinkedIn / Github / Google Scholar |

|
ResearchI'm interested in accelerated heterogeneous computing and applied machine learning. Most of my research focuses on pushing boundaries of algorithmic optimization with various accelerator architectures and applying AI to real-time autonomous systems. |

|
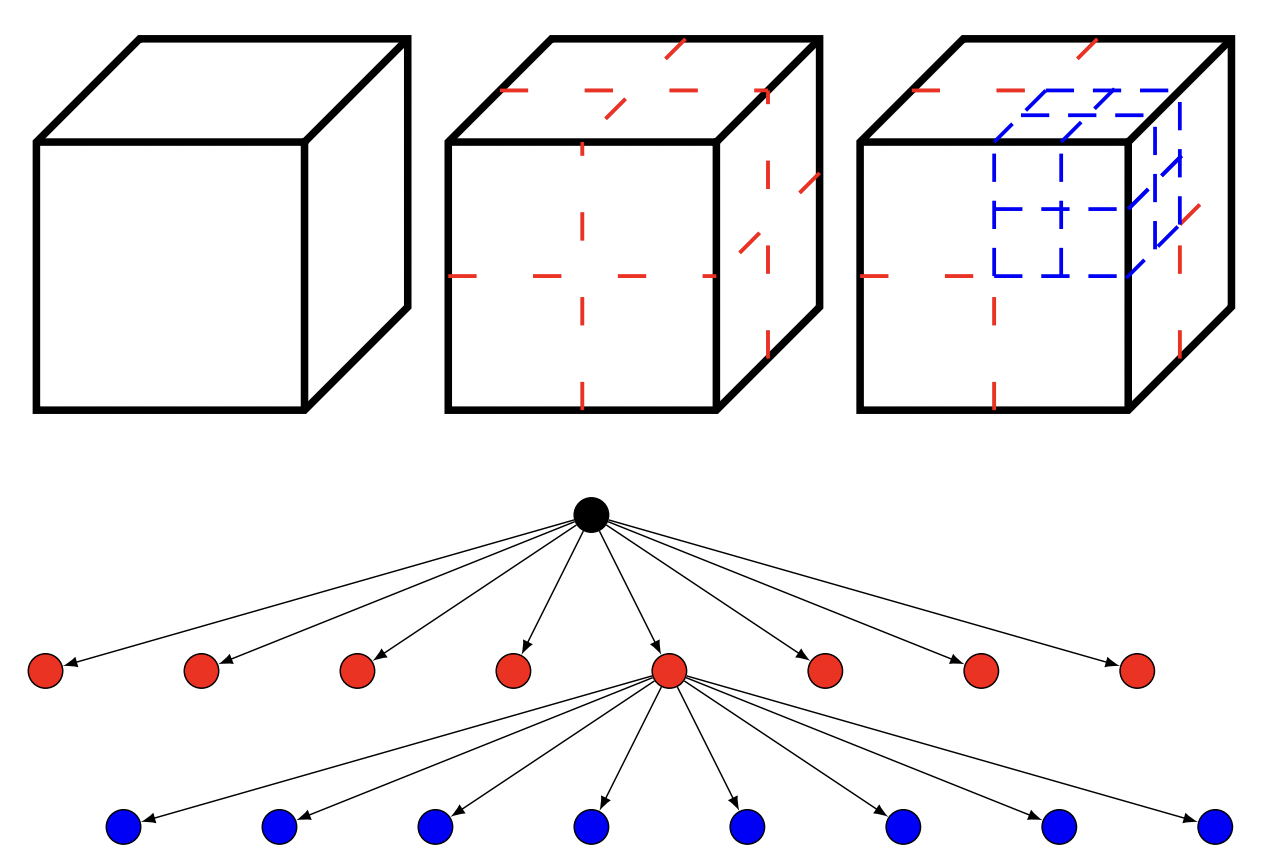
Efficient Data Movement for Machine Learning Inference in Heterogeneous CMS Software
Lukasz Michalski†, Christine Zeh†, Leonardo Beltrame, Davide Valsecchi, Felice Pantaleo, Eric Cano, 23rd International Workshop on Advanced Computing and Analysis Techniques in Physics Research, 2025 (Best Poster Award) Fast Machine Learning for Science Conference, 2025 7th IML Workshop on Machine Learning at the LHC, 2025 poster Efficient interface for heterogeneous machine learning inference inside cmssw framework enabling direct usage of optimized memory layouts (SoAs) with reduced memory footprint. |
|
Efficiency Analysis of Parallel Swarm Intelligence Using Rapid Range Search in Euclidean Space
Lukasz Michalski, Andrzej Soltysik, Marek Woda, International Journal of Electronics and Telecommunications, 2025 paper Originally presented at the 19th International Conference on Dependability of Computer Systems with a distinction for oral presentation, this research was later refined and published as a post-conference journal article. |

|
Parallel Swarm Intelligence: Efficiency Study with Fast Range Search in Euclidean Space
Lukasz Michalski, Andrzej Soltysik, Marek Woda, 19th International Conference on Dependability of Computer Systems, 2024 (Oral Presentation) bibtex / paper Optimizing swarm intelligence algorithms for large-scale simulation and rendering context using GPU acceleration and fast Euclidean range search. |
Other ProjectsThese include coursework, side projects, and unpublished research work. |
|
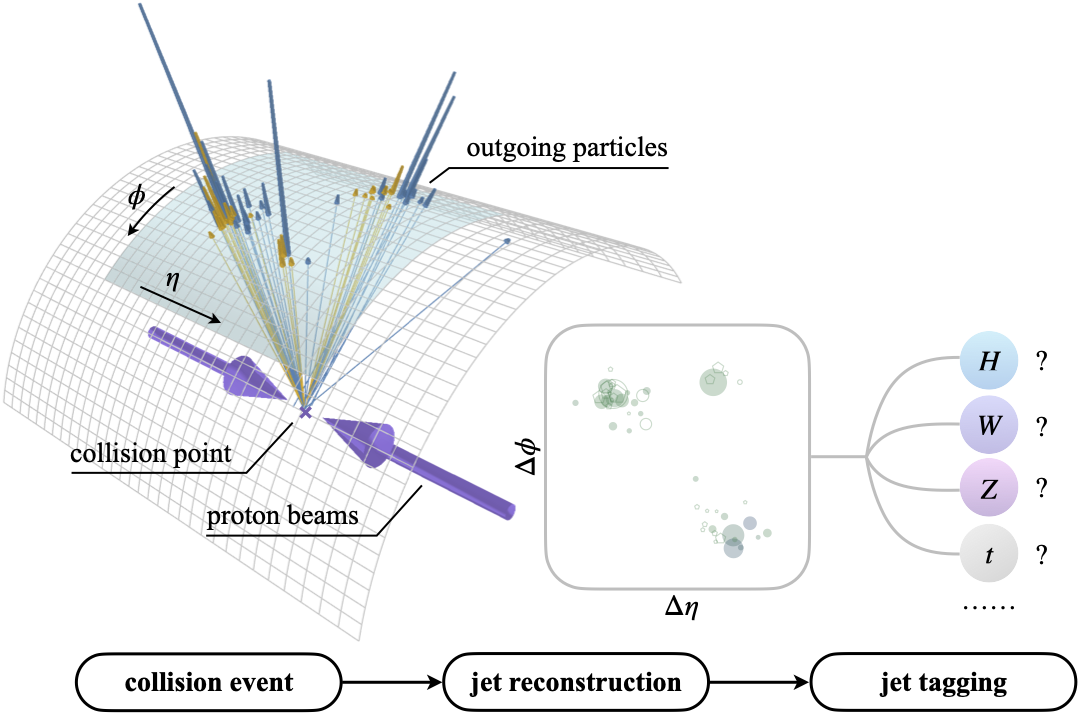
Real-Time and Quasi-Real-Time Data Acquisition and Physics Analysis Algorithms for the Level 1 Trigger System
Lukasz Michalski CERN & Wroclaw University of Science and Technology, 2026 Thesis Hardware accelerated W boson decay to three charged pions analysis algorithm for 40 MHz processing. Interface for efficient machine learning workloads in CMS software and concept of new approach of reconstruction and identification of hadronically decaying τ leptons at low pT |
|
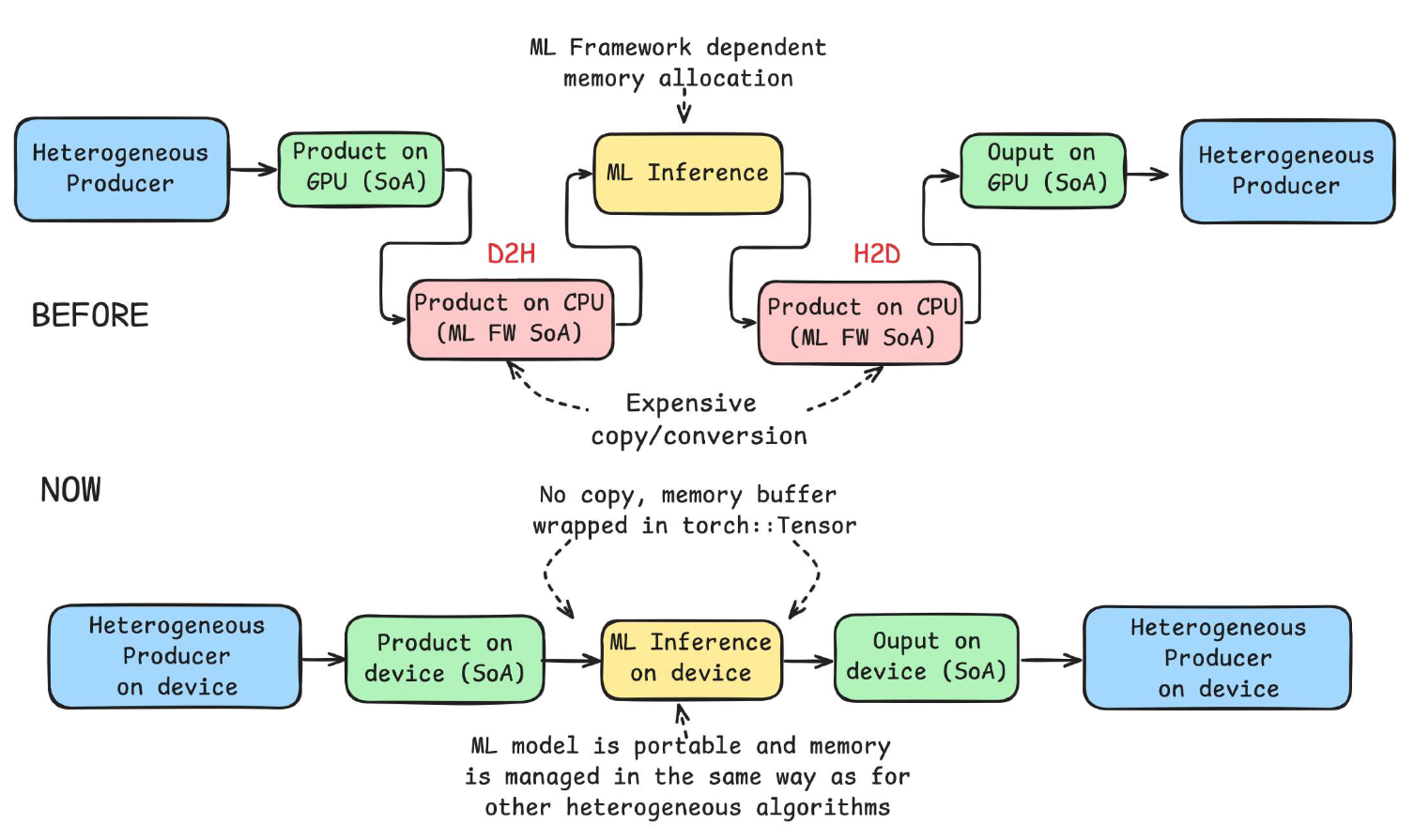
Foundations for Framework eXtensions
Lukasz Michalski†, Christine Zeh† CERN, CMS Collaboration, Next Generation Triggers, 2026 Foundations for Framework eXtensions (ffx) is an implementation of work published as part of Efficient Data Movement for Machine Learning Inference in Heterogeneous CMS Software in form of header-only library without cmssw framework dependencies. |
|
Ver2Vision: Verbal Data to Vision Synthesis with Latent Diffusion Models
Szymon Lopuszynski†, Lukasz Michalski†, Wojciech Rymer†, AI Forum, Wroclaw Univeristy of Science and Technology, 2025 student project What would your favorite book character look like? Our AI identifies characters from text and visualizes them realistically, bringing even non-adapted works to life for education, literary studies, and book promotion. |

|
Real Time Computer Vision System for Cone Detection
Lukasz Michalski PWR Racing Team, 2025 RT15e / Part Report High-performance, real-time cone detection system for autonomous Formula Student vehicles, utilizing YOLO architecture optimized with NVIDIA TensorRT to achieve low-latency, high-accuracy inference on end device. |
|
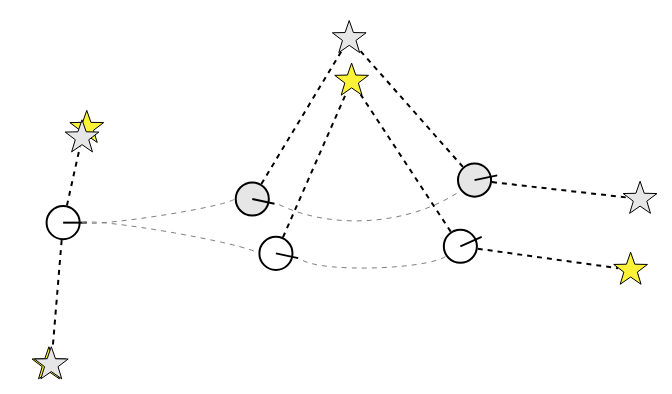
Benchmarking SLAM Algorithms for Autonomous Formula Student Vehicle
Lukasz Michalski PWR Racing Team, 2024 RT14e / Part Report Research and evaluation of various SLAM algorithms for autonomous Formula Student vehicles, focusing on real-time performance and accuracy in dynamic environments. |
|
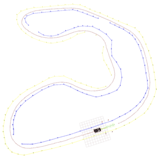
Dense Graph Network based Path Planning Algorithm with Geometric Raceline Optimization
Lukasz Michalski PWR Racing Team, 2024 Thesis / RT14e / Part Report A method for addressing real-time path planning challenges through Delaunay triangulation, random trees, and dense network representations for geometry-driven raceline optimization in Formula Student autonomous systems. |
Reference LettersRecommendations, endorsements, and other relevant references from professors, mentors, and supervisors who have collaborated with me on research, projects, or academic coursework are available upon request. |
|
Design and source code from Jon Barron's website |